สวัสดีครับ DevOps 101 ของเรา วันนี้ จะมาพูดถึง Filebeat นะครับ ..
Filebeat คืออะไร?
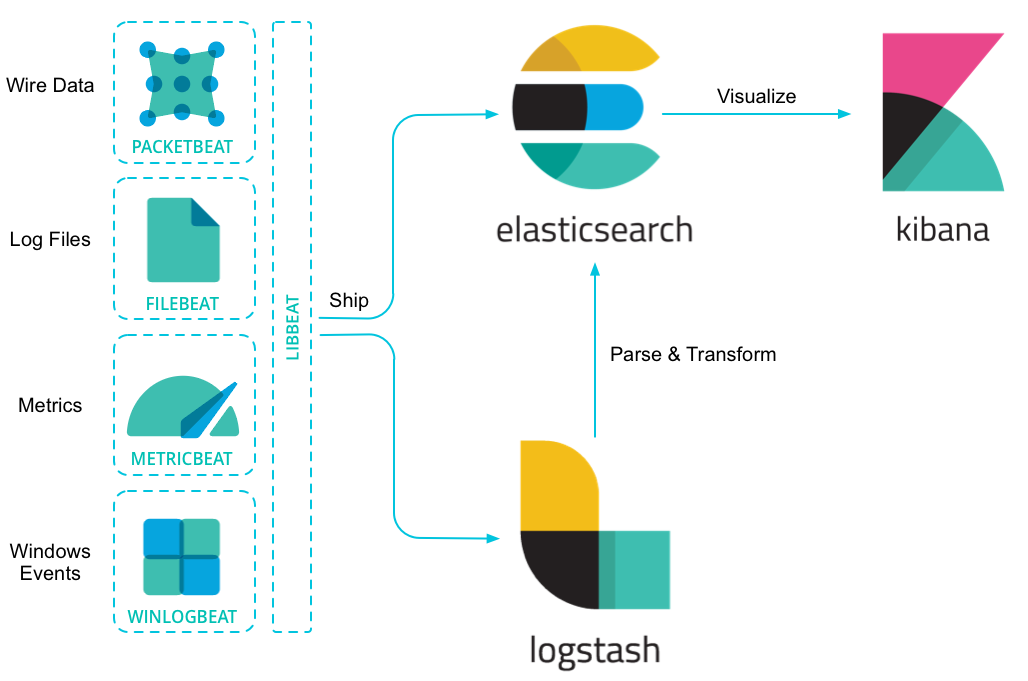
Filebeat = Lightweight shipper for logs
“Whether you’re collecting from security devices, cloud, containers, hosts, or OT, Filebeat helps you keep the simple things simple by offering a lightweight way to forward and centralize logs and files.”
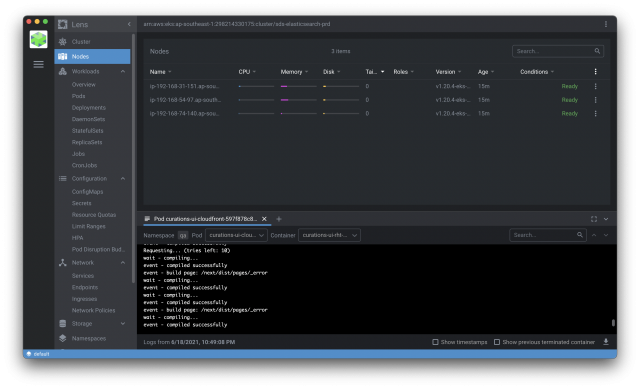
ถ้าเอาแบบเข้าใจง่ายๆ ก็คือ ตัวกวาด logs จากที่ต่างๆ เข้ามาที่ centralize logs ในที่นี้ ผมจะพูดถึง k8s cluster (EKS) logs ไปเก็บที่ Elasticsearch ละกันนะครับ ..
จริงๆ ยังมี ตัวอื่นๆ อีก นะครับ ที่ทำงานคล้ายๆ Filebeat เช่น Fluentd, Fluentbit
ในเมื่อเราใช้ ELK Stack ใน Ecosystem ของเราแล้ว การที่เราอยาก search logs ต่างๆ ที่เกิดจาก container ของเรา ได้ง่ายสุด ก็คือการ ship logs จาก k8s cluster ของเรา ไปเก็บไว้บน Elasticsearch แล้วทำการ search ผ่าน Kibana ..
วิธีการ Install Filebeat ใน k8s cluster
ทำได้หลายวิธีครับ ในที่นี้ ผมจะใช้วิธีง่ายๆ ผ่าน kubectl ดังต่อไปนี้
1. Create Secret โดยใส่ค่าที่จำเป็น พวกนี้ลงไป
– ELASTICSEARCH_HOST = Endpoint ของ Elasticsearch เรา
– ELASTICSEARCH_PORT = Port ที่ Elasticsearch เราทำงานอยู่
– ELASTICSEARCH_USERNAME = Username ของ Elasticsearch
– ELASTICSEARCH_PASSWORD = Password ของ Elasticsearch
– ELASTIC_CLOUD_ID = Cloud ID ในกรณีที่เราใช้ผ่าน Cloud Service ของ Elastic.co
– ELASTIC_CLOUD_AUTH = Username:Password ของ Elasticsearch
filebeat-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: filebeat
namespace: kube-system
type: Opaque
data:
ELASTICSEARCH_HOST: aHR0cDovL2xvY2FsaG9zdA==
ELASTICSEARCH_PASSWORD:
ELASTICSEARCH_PORT: OTIwMA==
ELASTICSEARCH_USERNAME:
ELASTIC_CLOUD_AUTH:
ELASTIC_CLOUD_ID:
จากนั้น สั่ง create secret
kubectl create -f filebeat-secret.yaml2. Create Deployment และ Resource อื่นๆ
filebeat-kubernetes.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
# To enable hints based autodiscover, remove `filebeat.inputs` configuration and uncomment this:
filebeat.autodiscover:
providers:
- type: kubernetes
node: ${NODE_NAME}
hints.enabled: true
hints.default_config:
type: container
paths:
- /var/log/containers/*${data.kubernetes.container.id}.log
# Filter by container.name
# filebeat.autodiscover:
# providers:
# - type: kubernetes
# node: ${NODE_NAME}
# templates:
# - condition:
# contains:
# kubernetes.container.name: "container01"
# config:
# - type: container
# paths:
# - "/var/log/containers/*-${data.kubernetes.container.id}.log"
# - condition:
# contains:
# kubernetes.container.name: "container02"
# config:
# - type: container
# paths:
# - "/var/log/containers/*-${data.kubernetes.container.id}.log"
processors:
- add_cloud_metadata:
- add_host_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
#index: "%{[fields.my_type]}-%{[agent.version]}-%{+yyyy.MM.dd}"
username: ${ELASTICSEARCH_USERNAME}
password: ${ELASTICSEARCH_PASSWORD}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:8.6.2
args: ["-c", "/etc/filebeat.yml", "-e"]
env:
- name: ELASTICSEARCH_HOST
valueFrom:
secretKeyRef:
name: filebeat
key: ELASTICSEARCH_HOST
- name: ELASTICSEARCH_PORT
valueFrom:
secretKeyRef:
name: filebeat
key: ELASTICSEARCH_PORT
- name: ELASTICSEARCH_USERNAME
valueFrom:
secretKeyRef:
name: filebeat
key: ELASTICSEARCH_USERNAME
- name: ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRef:
name: filebeat
key: ELASTICSEARCH_PASSWORD
- name: ELASTIC_CLOUD_ID
valueFrom:
secretKeyRef:
name: filebeat
key: ELASTIC_CLOUD_ID
- name: ELASTIC_CLOUD_AUTH
valueFrom:
secretKeyRef:
name: filebeat
key: ELASTIC_CLOUD_AUTH
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: varlog
mountPath: /var/log
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat-kubeadm-config
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
- apiGroups: ["apps"]
resources:
- replicasets
verbs: ["get", "list", "watch"]
- apiGroups: ["batch"]
resources:
- jobs
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat
# should be the namespace where filebeat is running
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs: ["get", "create", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups: [""]
resources:
- configmaps
resourceNames:
- kubeadm-config
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
---
จากนั้น สั่ง create deployment
kubectl create -f filebeat-kubernetes.yaml3. Search k8s cluster logs ผ่าน Kibana
ถ้า config ทุกอย่างเราถูกต้อง container ทำงานได้ เราก็จะได้ logs ของ k8s cluster เรา ไปเก็บบน Elasticsearch และทำการ search ผ่าน Kibana ได้เลย
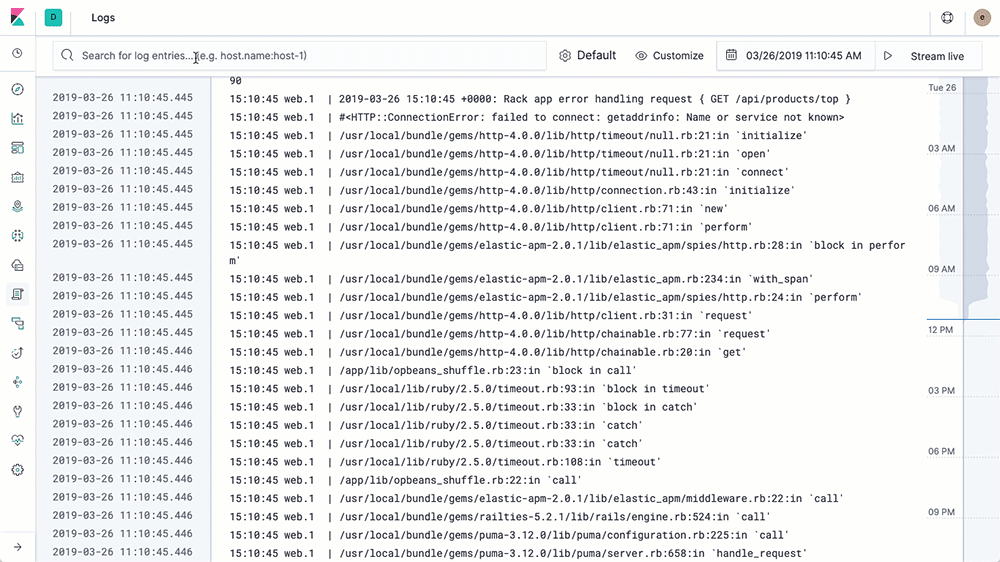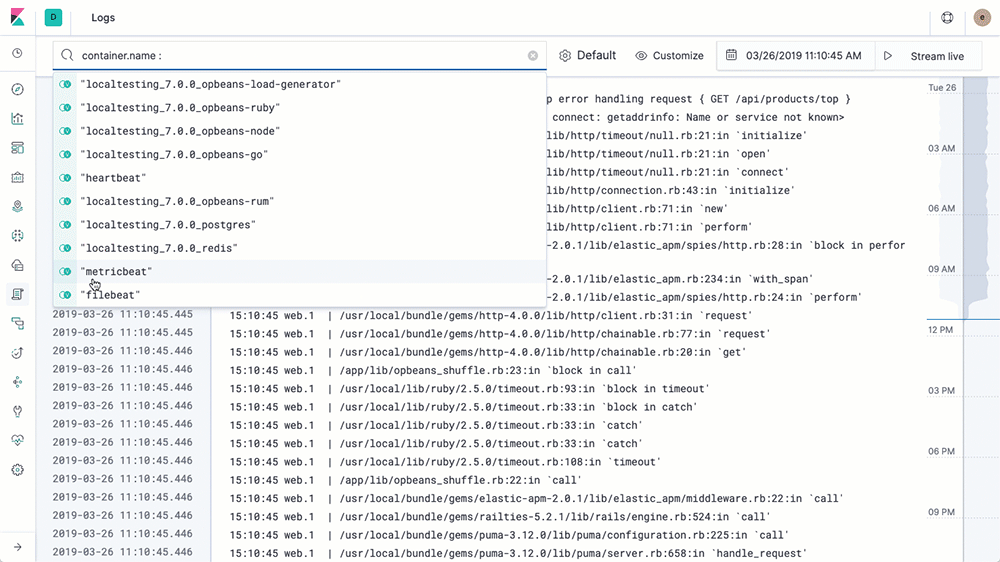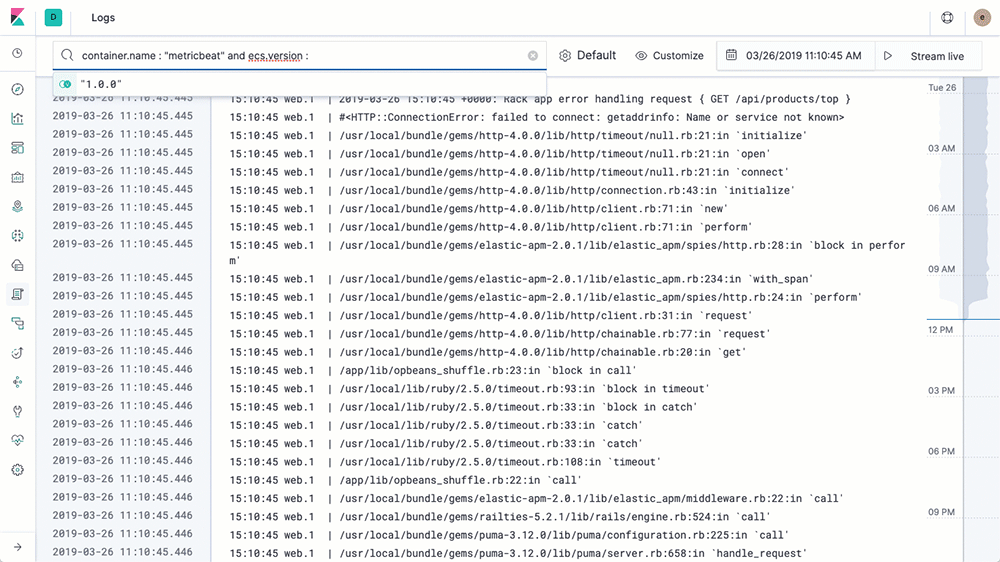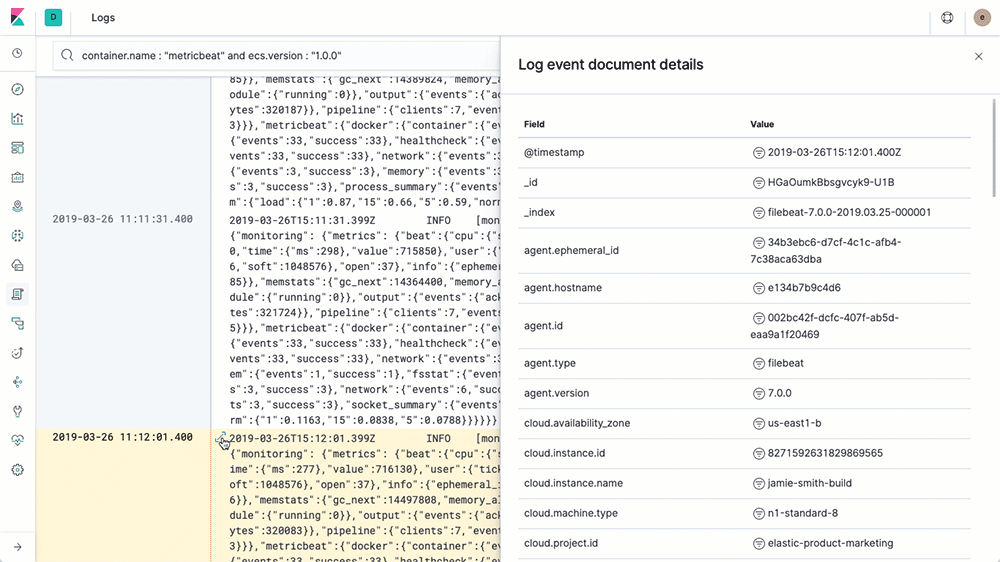
* เราสามารถ filter input ของ Logs ที่จะ ship ไปเก็บ ที่ Elasticsearch ได้
ตัวอย่างอยู่ใน filebeat-kubernetes.yaml ที่ comment ไว้
เป็นอย่างไรกันบ้างครับ ไม่ยากเลยใช่ไหมครับ สำหรับการ ship logs จาก k8s cluster ของเรา ไปเก็บบน Elasticsearch 🙂
Git Repo: https://github.com/pornpasok/k8s-logs-es-filebeat
Ref: https://www.elastic.co/beats/filebeat