สวัสดีครับ DevOps 101 ของเราวันนี้ นำเสนอ Lens ครับ .. ตอนนี้ ก็ออกมาถึง version 5.x.x กันแล้ว ณ ตอนที่ผมเขียน blog ก็เป็น version 5.1.3 เพื่อนๆ บางท่าน อาจจะเคยใช้งานกันมาบ้างแล้ว .. แต่สำหรับบางท่านที่ยังไม่เคยใช้งาน อาจจะยังสงสัยว่ามันคืออะไรกัน เจ้า Lens .. จากคำอธิบายในเว็บของเค้าคือ ..
“Lens is the only IDE you’ll ever need to take control of your Kubernetes clusters. It’s built on open source and free.”
สรุปสั้นๆ เข้าใจง่ายๆ ก็คือ Lens เป็น IDE ที่ช่วยจัดการ Kubernetes (k8s) cluster ของเรา เป็น Open Source และ Free 🙂
สำหรับท่านที่เคยใช้ kube-proxy ที่เป็น Dashboard ของ k8s เอง .. จะพบว่า มันใช้งานไม่ค่อยสะดวกเท่าไรนัก .. ลองเปลี่ยนมาใช้ Lens ดูครับ จะพบว่าสะดวกกว่ามากๆ ..
สำหรับวิธีการติดตั้ง Lens ก็ไป download ได้เลยครับที่ https://k8slens.dev/ มีทั้งบน Mac OS, Windows และ Linux ครับ .. ตัว Lens เองจะใช้ file config เดียวกับ kubectl ของเราคือจะอยู่ที่ ~/.kube/config ซึ่งถ้าใครใช้งาน kubectl ได้อยู่แล้ว ก็จะไม่มีปัญหา อะไร .. แต่ถ้าเปิด Lens ขึ้นมาแล้ว ยังใช้งานไม่ได้ ก็ให้ไปลองดูที่ ~/.kube/config ว่ามีค่า config ต่างๆ ถูกต้องไหม .. หรือถ้าใครใช้ EKS อยู่ วิธีการง่ายๆ ก็คือ การสั่ง update kube config ครับ ดังตัวอย่าง ..
aws eks update-kubeconfig --name tono-eks \
--region ap-southeast-1 \
--profile tono-adminสิ่งที่อยากจะนำเสนอเพิ่มเติม สำหรับเจ้า Lens ก็คือ Lens Metrics ซึ่งตรงนี้ จะทำให้เราดู resource ของ k8s cluster เราได้ง่ายขึ้น สะดวกขึ้นครับ .. จริงๆ แล้ว ก็คือการติดตั้ง Prometheus + Kube State Metrics + node exporter เข้าไป เพื่อเก็บ metrics ต่างๆ จาก k8s cluster เราลงบน Prometheus นั่นเองครับ .. มาดูวิธีการ enable ตรงนี้กันครับ ..
1.คลิกขวาที่ icon ของ k8s cluster ของเรา แล้วเลือก Settings
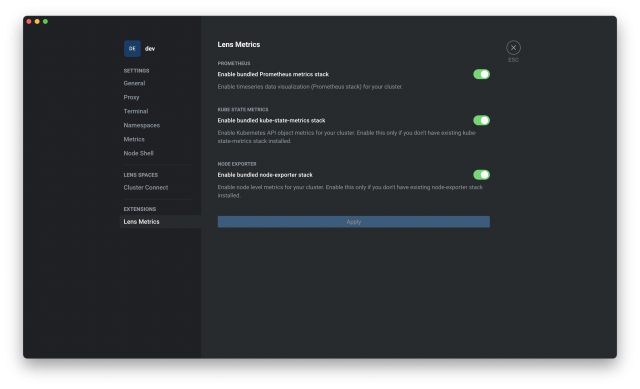
2.มาที่ Lens Metrics แล้วทำการ Enable PROMETHEUS, KUBE STATE METRICS, NODE EXPORTER จากนั้นกด Apply
3.กลับมาที่หน้าหลักของ Lens ไปที่ Workloads > Pods ก็จะเห็นว่า pods ต่างๆ ที่เกี่ยวข้องกับ Lens Metrics ของเราเขียวแล้ว
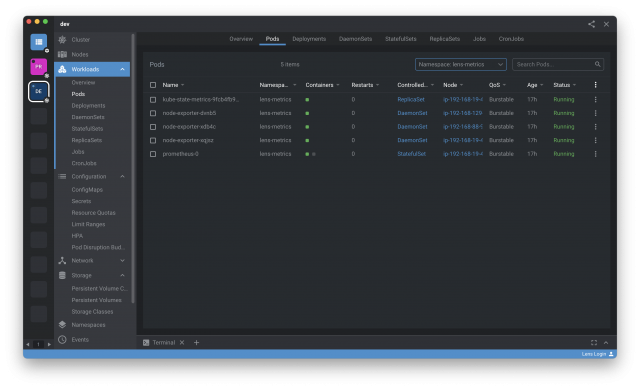
4.กดไปที่ Cluster หรือ Nods ก็จะเห็น Metrics ต่างๆ แสดงผลแล้วครับ
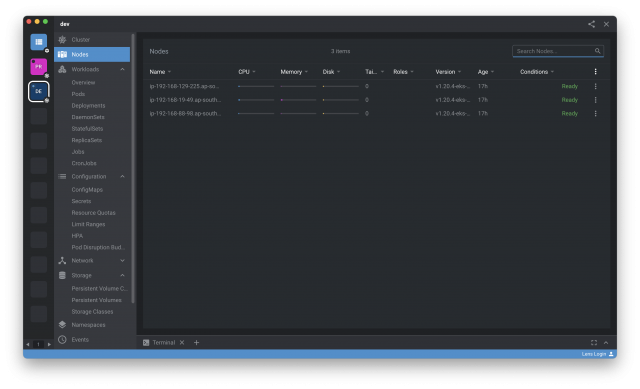
ขั้นตอนต่างๆ ก็ง่ายๆ ประมาณนี้ครับ เราก็จะได้ Lens Metrics ที่เป็น Dashboard & Monitoring สำหรับ ดู รายละเอียดต่างๆ ของ k8s cluster ของเรากันแล้วครับ ..
Update!!! (2021-09-25) Grafana Dashboard
วันนี้ มา update การทำ Dashboad & Monitoring ของ k8s cluster ที่จะดูได้ละเอียดกว่านี้ ด้วย Grafana ครับ ..
หลายๆ ท่าน คงอยากมี dashboard (Grafana) เอาไว้ดู metrics ต่างๆ ของ k8s cluster ของเรา ให้คนในทีมได้เอาไว้ดู ในทุกที่ ทุกเวลา .. ซึ่งเราก็สามารถติดตั้งได้ผ่าน Lens เลยครับ โดยมีขั้นตอน เพิ่มเติมดังนี้ ..
1.ไปที่ Apps > Charts แล้ว search “prometheus-operator”
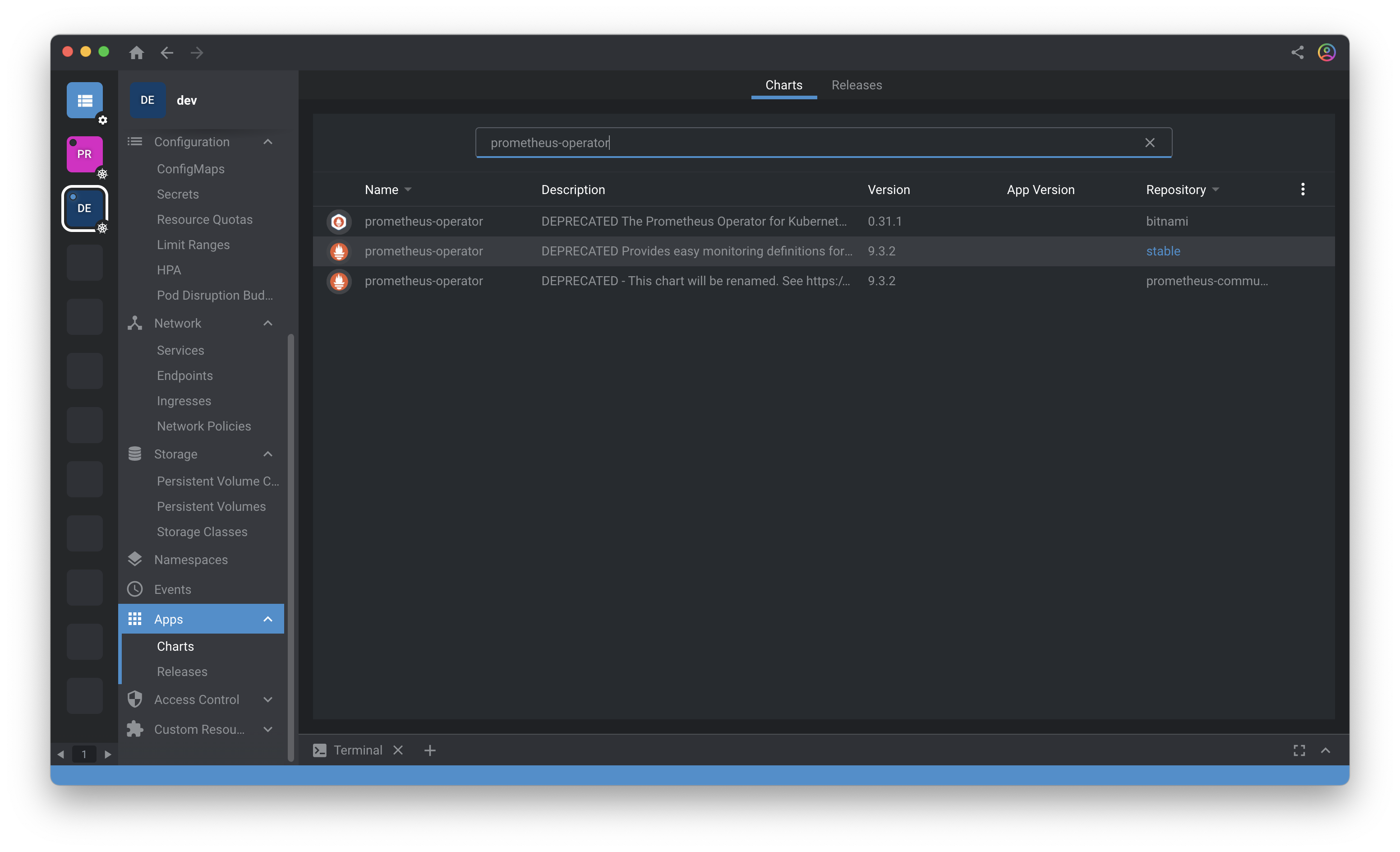
2.กด install ใน namespace ที่เราต้องการ ในที่นี้ผม create ns ชื่อ prometheus มาเพิ่มเติม
หรือถ้าอยากลอง install เอง ก็สามารถทำตามขั้นตอน ของ prometheus-operator ได้ตามนี้เลยครับ ..
[Link] https://github.com/prometheus-operator/prometheus-operator
3.ไปที่ Network > Services จะพบ service ที่ชื่อ “prometheus-operator-xxx-grafana”
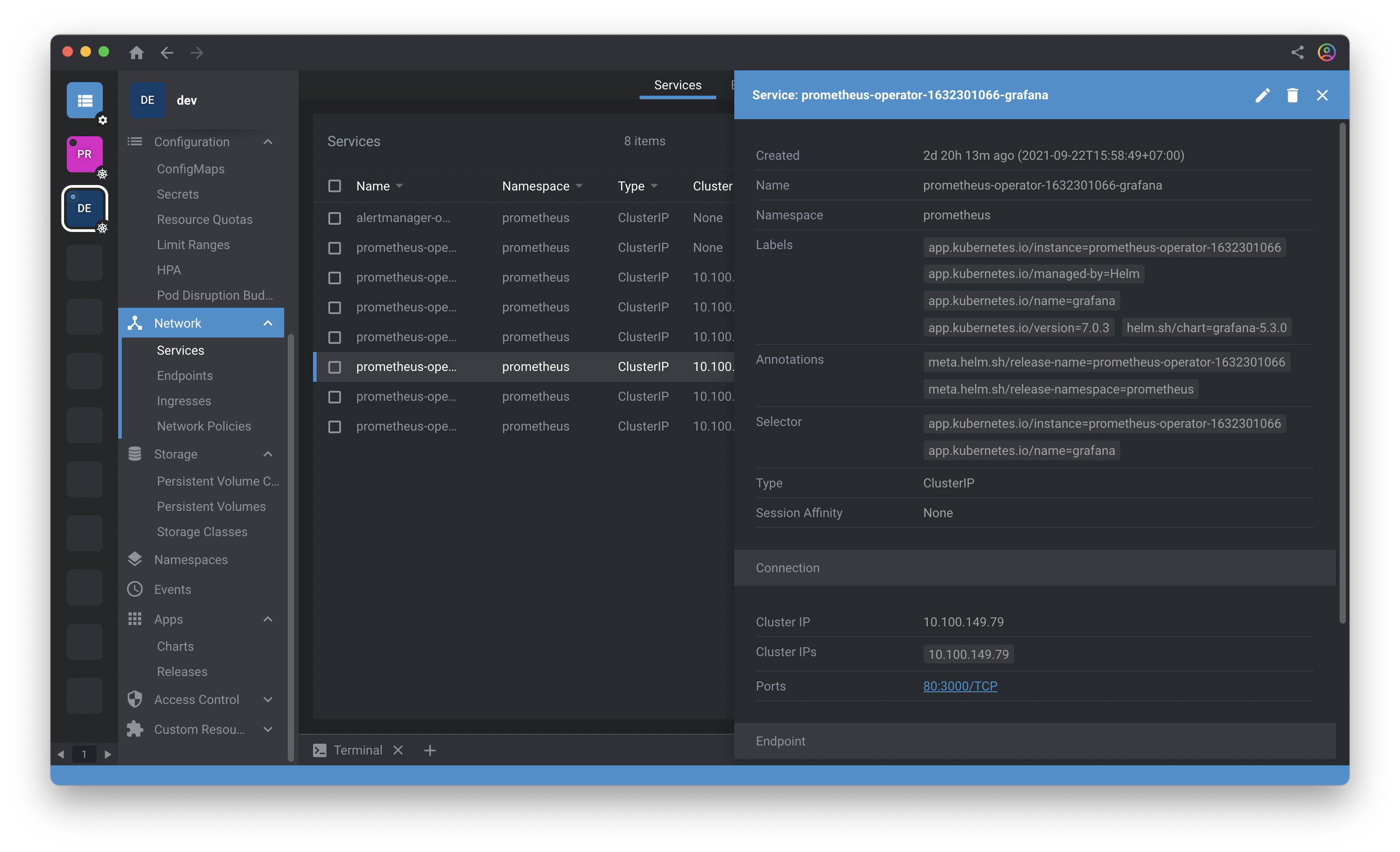
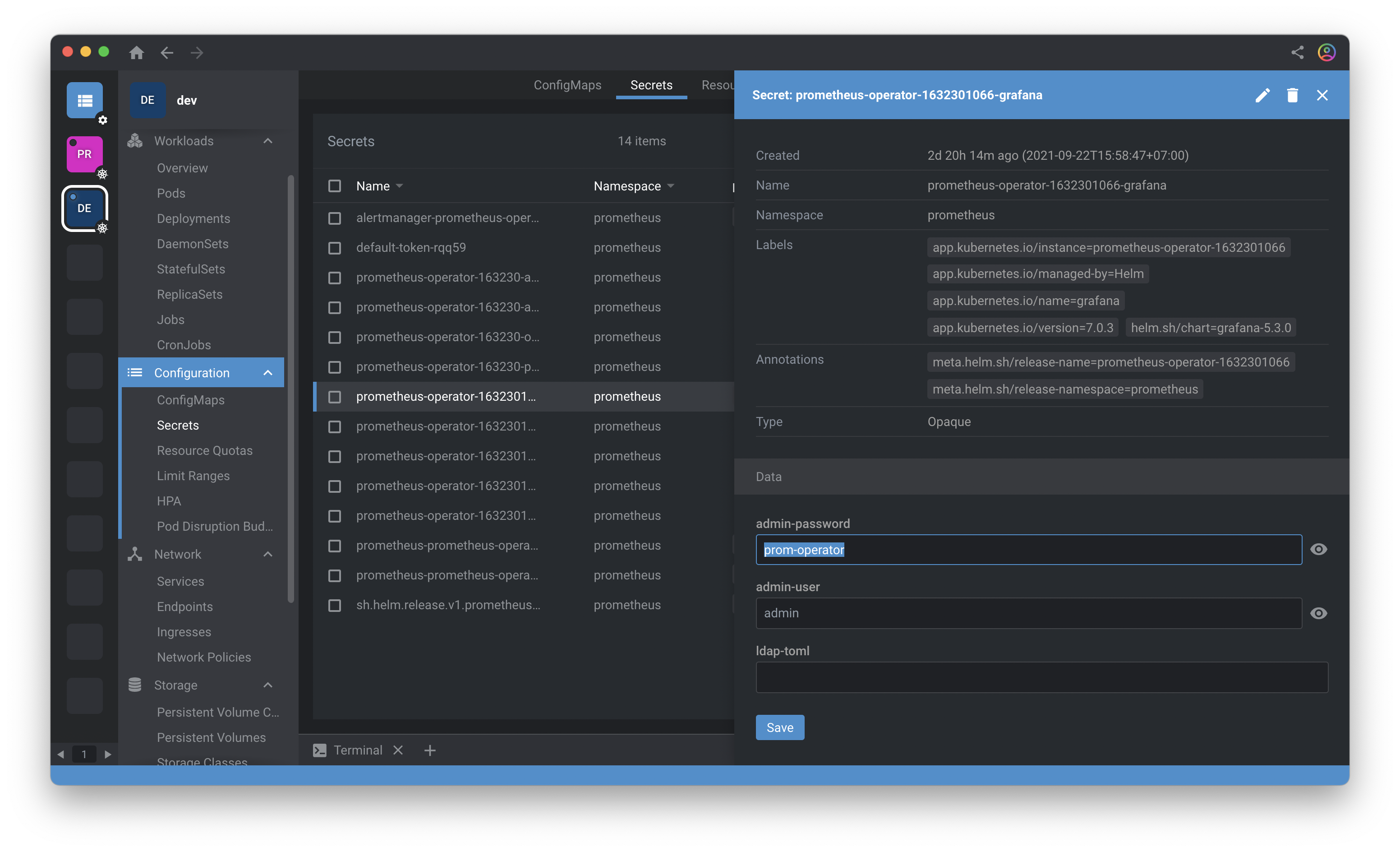
4.ทำการ login เข้า Grafana โดย default user-password สามารถดูได้ที่ Configuration > Secrets เลือกดู secret “prometheus-operator-xxx-grafana”
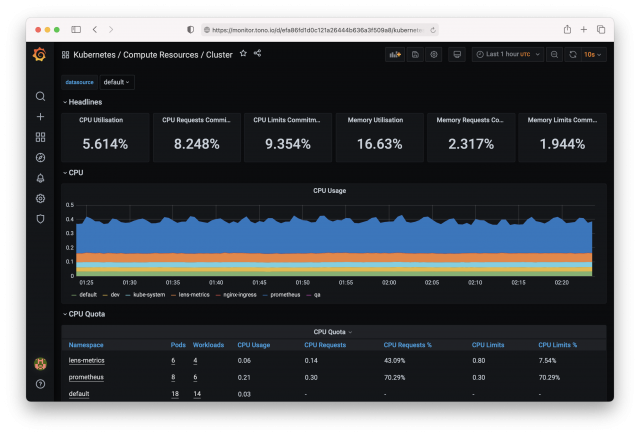
5.ไปที่ Dashboard จะเห็นว่า มี k8s cluster dashboard ที่จำเป็นมาให้เราเรียบร้อย
เป็นอย่างไรกันบ้างครับ ไม่ยากเลยใช่ไหมครับ? แต่การที่เราจะ expose Grafana dashboard ของเรา ให้คนอื่น สามารถเข้ามาได้นั้น เราต้องมี ingress มาต่อ กับ service grafana ของเราด้วยนะครับ .. ในครั้งต่อไป ผมจะมาพูดถึงการสร้าง ingress ให้กับ k8s cluster ของเรากันครับ .. 🙂
มาต่อกันครับ ในขั้นตอนการทำให้ Grafana ของเรา สามารถเข้าจากที่ไหน ก็ได้
6. สร้าง Ingress ให้กับ Grafana เรา ให้สามารถเข้าดูจาก public ได้
ในที่นี้ ผมจะ ทำการ create ingress ให้กับ Grafana ของเรากันครับ ด้วย manifest (YAML) ประมาณนี้
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: prometheus
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: grafana.domain.com
http:
paths:
- backend:
serviceName: prometheus-operator-xxx-grafana
servicePort: 80
7. ทำการ Add CNAME record ของ Grafana มาที่ Ingress Endpoint ของเรา
อย่างในที่นี้ ผมใช้บริการ DNS ของ CloudFlare อยู่ ผมก็จะไป Add เพิ่ม ประมาณนี้ครับ

เพียงเท่านี้ เราก็จะสามารถเรียกใช้งาน URL ของ Grafana จากที่ไหน ก็ได้แล้วครับ ..